
1、“sql分类”
在使用sql的过程中,笔者从易到难一共遇到了这几类sql。
1.1、“简单”sql
即不需要任何的额外操作,条件什么的都是固定死的,这一类被笔者称为”简单“sql
例如:
select * from xx where xx=#{xx}1.2、“中等”sql
即需要对where条件进行动态调整,也就是常说的动态sql这一类。
例如:
select * from xxx
<where>
<if test="condition"> xx = #{xx} </if>
...
<if test="condition"> xx = #{xx} </if>
</where>其中还包括<trim>\<set>\<choose>等其他的标签,后续再开一贴记录一下这些标签。
1.3、“复杂”sql
说是复杂sql但实际上写起来却是比“中等”的更加简单。即动态的根据入参拼接sql,再执行。
例如:
select * from xxx
<where>
1=1
<if test="info!=null and info!=''">
<if test="info.sql!=null and info.sql!=''">
${info.sql}
</if>
</if>
</where>
info.sql是入参对象的一个属性。下面主要讲”复杂“sql。
2、复杂sql原理及实现
原理是通过拦截器拦截即将执行的sql,再通过入参与提前制定好的规则动态的修改sql,并将占位的"?"替换成真实的参数。最终交由mybatis执行。接下来讲讲怎么实现sql拦截器。
2.1、mybatis-plus
依赖版本mybatis-plus-boot-starter 3.5.6
使用plus是因为可以直接用plus的warpper类,方便对sql进行操作。
QueryWrapper<Object> wrapper;
public ConcatWrapper() {
this.wrapper = new QueryWrapper<>();
}
public void or() {
wrapper.or();
}
public void like(String column, String val) {
wrapper.like(column, val);
}
public void notLike(String column, String val) {
wrapper.notLike(column, val);
}
public void isNull(String column, String val) {
wrapper.isNull(column);
}
public void isNotNull(String column, String val) {
wrapper.isNotNull(column);
}
public void eq(String column, String val) {
wrapper.eq(column, val);
}
public void gt(String column, String val) {
wrapper.gt(column, val);
}
public void lt(String column, String val) {
wrapper.lt(column, val);
}
public void ge(String column, String val) {
wrapper.ge(column, val);
}
public void le(String column, String val) {
wrapper.le(column, val);
}
public void ne(String column, String val) {
wrapper.ne(column, val);
}
public void in(String column, String val) {
wrapper.in(column, this.splitByComma(val));
}
public void notIn(String column, String val) {
wrapper.notIn(column, this.splitByComma(val));
}
public void between(String column, String val) {
List<String> values = this.safeBetWeen(val);
wrapper.between(column, values.get(0), values.get(1));
}
public void dateBetween(String column, String val) {
Calendar calendar=Calendar.getInstance();
try {
List<String> dateStr = this.safeBetWeen(val);
Date startTime = DateUtil.parseDate(dateStr.get(0));
calendar.setTime(DateUtil.parseDate(dateStr.get(1)));
calendar.add(Calendar.DAY_OF_MONTH,1);
Date endTime = calendar.getTime();
wrapper.between(column, Timestamp.from(startTime.toInstant()), Timestamp.from(endTime.toInstant()));
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException("请指定正确的时间格式!");
}
}
private List<String> safeBetWeen(String val) {
List<String> values = this.splitByComma(val);
if (values.size() != 2)
throw new RuntimeException("检查值【" + val + "】,条件列运算符为之间时,值只能传入两个参数!");
return values;
}
private List<String> splitByComma(String val) {
if (null == val) throw new RuntimeException("查询条件不要传入空值!");
String[] tarArr = val.trim().split(StrPool.COMMA);
return Arrays.asList(tarArr);
}
public static MethodHandles.Lookup lookup() {
return MethodHandles.lookup();
}
public String getSqlSeg() {
String targetSql = wrapper.getTargetSql();
StringBuilder sqlSeg = new StringBuilder(StringPool.AND.length() + targetSql.length() + 16);
sqlSeg.append(StringPool.AND);
Map<String, Object> sqlParamMap = wrapper.getParamNameValuePairs();
Object[] paramArr = sqlParamMap.entrySet().stream()
.collect(Collectors.groupingBy(entry -> entry.getKey().length()))
.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue().stream()
.sorted(Map.Entry.comparingByKey())
.map(Map.Entry::getValue)
.collect(Collectors.toList())))
.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.flatMap(entry -> entry.getValue().stream())
.toArray();
char zw = '?';
int paramIdx = 0;
for (int i = 0; i < targetSql.length(); i++) {
char c = targetSql.charAt(i);
if (c == zw) {
sqlSeg.append(StringPool.SINGLE_QUOTE);
sqlSeg.append(paramArr[paramIdx]);
paramIdx++;
sqlSeg.append(StringPool.SINGLE_QUOTE);
} else {
sqlSeg.append(c);
}
}
return sqlSeg.toString();
}大致可以看出来,包含了很多的连接条件,例如eq、like之类的。getSqlSeg()这个方法则是对sql进行预编译,并将sql中占位的”?“替换成实际的参数。
2.2、入参
既然是自定义查询,那么是什么东西可以自定义呢?where条件后面全部的数据都可以自定义!包括参数名、参数值、匹配条件、连接条件。
既如此,那么入参就不能像以前一样,直接定义成参数名了,那根据需要尝试推理出需要些什么参数吧。
首先字段名、字段值、连接条件、匹配条件是不能少的,这样一来就4个参数了。
其次,字段对应的表名也应该有,有备无患。表名都有了,别名也加上,万一sql里面写了别名呢?
最后字段对应的中文也得有,毕竟前端展示可不能直接展示英文字段。
那么到此,入参的DTO长什么样就大致清晰了。
@ApiModelProperty(当前sql表别名")
private String tableAlias;
@ApiModelProperty("数据库表名")
private String dbTableName;
@ApiModelProperty("数据库字段名")
private String dbColumnName;
@ApiModelProperty("操作符:例如大于、小于、之间……")
private Integer operator;
@ApiModelProperty("值")
private String value;
@ApiModelProperty("条件逻辑关系:0-->and;1-->or")
private Integer relationType;
@ApiModelProperty("列标题")
private String title;Q::这只是一个查询条件,如果需要多个,又当如何?
A:用一个List接收即可。
因此,实际的入参应该是这样的:
private String sqlSegment;
@ApiModelProperty("查询列及运算条件")
private List<QueryColumnDTO> queryColumns;
@ApiModelProperty("表对应id")
private Integer tableId;
public List<QueryColumnDTO> getQueryColumns() {
return null == queryColumns ? Collections.emptyList() : queryColumns;
}2.3、切面拦截
首先定义一个注解,注解叫什么随意。这个注解需要打在mapper层。
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface SelfQuery {
}然后写切面类,切面类需交由spring容器管理。
@Aspect
@Component
@RequiredArgsConstructor
public class SelfQueryAOP {
private final SelfConcatService selfConcatService;
@Before("@annotation(com.hwb.customsql.aop.self.SelfQuery)")
public void vw(JoinPoint joinPoint) {
Object[] args = joinPoint.getArgs();
for (Object arg : args) {
if (!(arg instanceof SelfQueryViewDTO)) continue;
SelfQueryViewDTO dto = (SelfQueryViewDTO) arg;
// 入参条件
List<QueryColumnDTO> queryColumns= dto.getQueryColumns();
// 获取注解与方法信息
MethodSignature ms = (MethodSignature) joinPoint.getSignature();
//得到注解方法的全限定名
String mapperId = ms.getDeclaringTypeName() + StringPool.DOT + ms.getName();
// 填充别名
selfConcatService.fillTableAlias(queryColumns, mapperId);
// 拼接WHERE片段
String sqlSegment = selfConcatService.concatSql(queryColumns);
// 填充参数
dto.setSqlSegment(sqlSegment);
}
}
}在切面中完成了参数的拼接工作,并将拼接好的参数赋值给了入参DTO的sqlSegmnt这个值。后续sql中也是获取sqlSegment这个值。
切面中还有两个方法,一个是填充别名,一个是拼接where条件
2.3.1、填充表的别名
实现类实现接口,继承JsqlParserSupport 类,以此获得操作sql的能力。
public class SelfConcatServiceImpl extends JsqlParserSupport implements SelfConcatService代码如下:
public void fillTableAlias(List<QueryColumnDTO> queryColumns, String mapperId) {
if (CollectionUtil.isEmpty(queryColumns)) return;
MappedStatement statement = sqlSessionFactory.getConfiguration().getMappedStatement(mapperId);
BoundSql boundSql = statement.getBoundSql(null);
super.parserSingle(boundSql.getSql(), queryColumns);
}可以通过查看源码得知,super.parseSingle()这个方法,最终会抛出一个JsqlParserSupport 异常。
public String parserSingle(String sql, Object obj) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("original SQL: " + sql);
}
try {
Statement statement = JsqlParserGlobal.parse(sql);
return this.processParser(statement, 0, sql, obj);
} catch (JSQLParserException var4) {
throw ExceptionUtils.mpe("Failed to process, Error SQL: %s", var4.getCause(), new Object[]{sql});
}
}
/*分割线*/
protected String processParser(Statement statement, int index, String sql, Object obj) {
if (this.logger.isDebugEnabled()) {
this.logger.debug("SQL to parse, SQL: " + sql);
}
if (statement instanceof Insert) {
this.processInsert((Insert)statement, index, sql, obj);
} else if (statement instanceof Select) {
this.processSelect((Select)statement, index, sql, obj);
} else if (statement instanceof Update) {
this.processUpdate((Update)statement, index, sql, obj);
} else if (statement instanceof Delete) {
this.processDelete((Delete)statement, index, sql, obj);
}
sql = statement.toString();
if (this.logger.isDebugEnabled()) {
this.logger.debug("parse the finished SQL: " + sql);
}
return sql;
}
/*分割线*/
protected void processInsert(Insert insert, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
protected void processDelete(Delete delete, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
protected void processUpdate(Update update, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}
protected void processSelect(Select select, int index, String sql, Object obj) {
throw new UnsupportedOperationException();
}可以看出,经过层层调用,最终抛出异常,那么该如何解决呢?答案是重写这个方法。
重写后的select方法
protected void processSelect(Select select, int index, String sql, Object obj) {
List<QueryColumnDTO> queryColumns = (List<QueryColumnDTO>) obj;
PlainSelect plainSelect = (PlainSelect) select.getSelectBody();
for (QueryColumnDTO queryColumn : queryColumns) {
Table table = getTableByName(plainSelect, queryColumn.getDbTableName());
if (ObjectUtil.isNotNull(table) && ObjectUtil.isNotNull(table.getAlias())) {
queryColumn.setTableAlias(table.getAlias().getName());
} else {
queryColumn.setTableAlias(queryColumn.getDbTableName());
}
}
}循环中是对别名进行填充,如果sql中对表起了别名,字段名任然用”表名.字段名“,会抛出SQLSyntaxErrorException异常。
如果sql并未对表取别名,则按照入参的表名进行填充,即取”表名.字段名“。getTableByName是一个抽象出来的方法核心是一个循环,PlainSelect中包含了所有的sql信息,其中foritem可以强转为Table对象,从而获取别名。
下面是getTableByName方法:
public Table getTableByName(PlainSelect plainSelect, String dbTableName) {
Table table = new Table();
List<Table> tables=new ArrayList<>();
Table fromItem = (Table)plainSelect.getFromItem();
tables.add(fromItem);
List<Join> joins = plainSelect.getJoins();
for (Join join : joins) {
tables.add((Table) join.getFromItem());
}
for (Table table1 : tables) {
if (table1.getName().equals(dbTableName)) {
table=table1;
break;
}
}
return table;
}该工具类的作用是,获取主表和连接表的Table对象并和传入的数据库表名进行对比,起到一个匹配别名的作用。
两层循环起到一个为每一个入参匹配别名的作用。
2.3.2、拼接WHERE片段
代码如下:
private final HashMap<Integer, MethodHandle> opMh = new HashMap<>(OperatorEnum.values().length << 2);
{
MethodType mt = MethodType.methodType(void.class, String.class, String.class);
MethodHandles.Lookup lookup = ConcatWrapper.lookup();
for (OperatorEnum value : OperatorEnum.values()) {
String wrapperMethodName = value.getWrapperMethodName();
try {
MethodHandle mh = lookup.findVirtual(ConcatWrapper.class, wrapperMethodName, mt);
opMh.put(value.getState(), mh);
} catch (NoSuchMethodException | IllegalAccessException e) {
e.printStackTrace();
throw new RuntimeException("有操作符没有对应的SQL拼接方法,请检查操作符!" + value.getStateName());
}
}
}
public String concatSqlByMh(List<QueryColumnDTO> queryColumns) {
if (CollectionUtil.isEmpty(queryColumns)) return "";
ConcatWrapper wrapper = new ConcatWrapper();
for (QueryColumnDTO queryColumn : queryColumns) {
String column;
column = StrUtil.isBlank(queryColumn.getTableAlias()) ? queryColumn.getDbTableName() : queryColumn.getTableAlias()
+ StringPool.DOT + queryColumn.getDbColumnName();
try {
if (NumsConstant.INTEGER_ONE.equals(queryColumn.getRelationType())) {
wrapper.or();
}
MethodHandle mh = opMh.get(queryColumn.getOperator());
mh.invoke(wrapper, column, queryColumn.getValue());
} catch (Throwable e) {
e.printStackTrace();
throw new RuntimeException("字段[" + queryColumn.getDbTableName() + StringPool.DOT + queryColumn.getDbColumnName() + "]参数错误!");
}
}
return wrapper.getSqlSeg();
}回顾一下之前的入参条件,包含了连接条件、匹配条件。这里通过代码块对构造器进行了增强。通过先前定义的warpper,以及填充好的别名,对入参字段进行组装,拼接好sql,再通过warpper.getSqlSeg()对sql进行预编译,将?占位符替换成真正的入参,最终将这个字符串赋值给入参DTO的sqlSegment字段。
3、执行sql
写在xml文件里的sql长这个样子:
<select id="selfQuery" resultType="java.lang.Integer">
select count(*)
from ec_electric_supervise ees
inner join ec_equipment ee on ees.es_id=ee.id
<where>
1=1
<if test="info !=null and info !=''">
${info.sqlSegment}
</if>
</where>
</select>下面是测试入参,其中tablerId是瞎填的。由于需要维护一个表,表中包含了字段名、字段备注、字段对应的表,表的编号,用途是对不同的页面进行不同的查询字段进行归类,例如在实际生产中,页面A由表A、B、C的联表查询而来,那么表D的参数自然不能出现在这里,且未参与查询的列,也不应当出现在where条件中,因此需要一个id来将这些参数归类。不至于使得页面A的查询参数页面B也能看到。这里只是为了演示效果,所以并未对查询列做要求,随意选了两个列进行演示。
{
"queryColumns": [
{
"dbTableName": "ec_electric_supervise",
"dbColumnName": "es_id",
"operator": 1,
"value": "1",
"relationType": 1,
"title": "esId"
},
{
"dbTableName": "ec_equipment",
"dbColumnName": "equip_name",
"operator": 5,
"value": "E00001",
"relationType": 2,
"title": "equipName"
}
],
"tableId": 15
}接下来是控制台的输出,将日志级别调成debug,可以看到如下输出:
original SQL: select count(*)
from ec_electric_supervise ees
inner join ec_equipment ee on ees.es_id=ee.id
WHERE 1=1
/*分割线*/
SQL to parse, SQL: select count(*)
from ec_electric_supervise ees
inner join ec_equipment ee on ees.es_id=ee.id
WHERE 1=1
/*分割线*/
select count(*) from ec_electric_supervise ees inner join ec_equipment ee on ees.es_id=ee.id WHERE 1=1 and(ees.es_id LIKE '%1%' AND ee.equip_name = 'E00001')
Parameters:
<== Total: 1
21528分别对应了目录2.3节的源码,打印原始的SQL,打印解析后的SQL,以及打印执行的SQL。
到此拦截器修改SQL便算是成功了。
mybatis应该也是可以的,但是没有实际操作过,感兴趣的可以按照这个思路试试。mybatis可能需要导入额外的依赖。
3、知识点回顾&细节解释
3.1、SQL拦截器
SQL拦截器jsqlparser是mybatis-plus-core这个包下面的东西,如果是用的mybatis的话,需要另外引入jsqlparser这个依赖
SQL拦截器的功能不止于此,其中的PlainSelect对象包含了即将执行的SQL的全部信息,如图所示

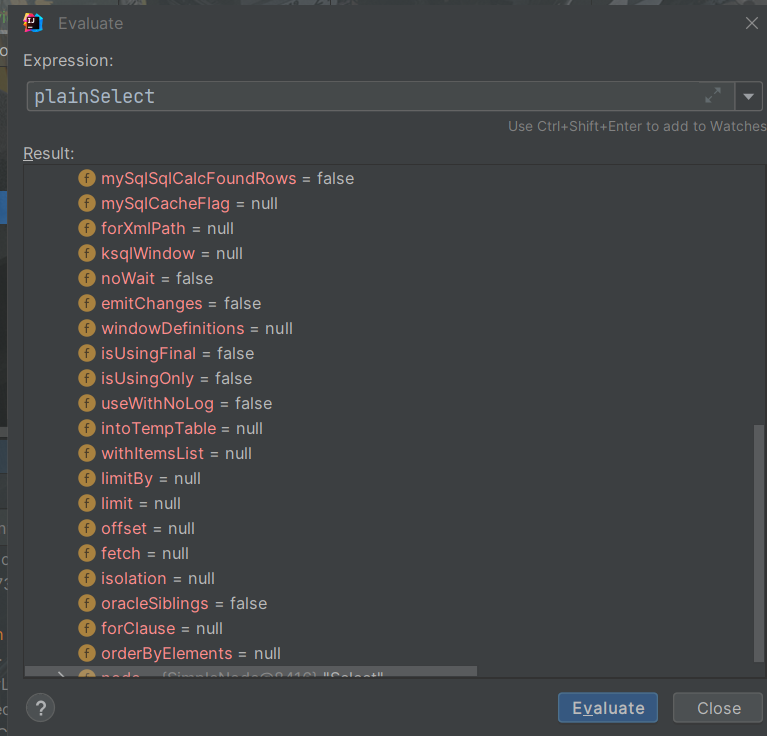
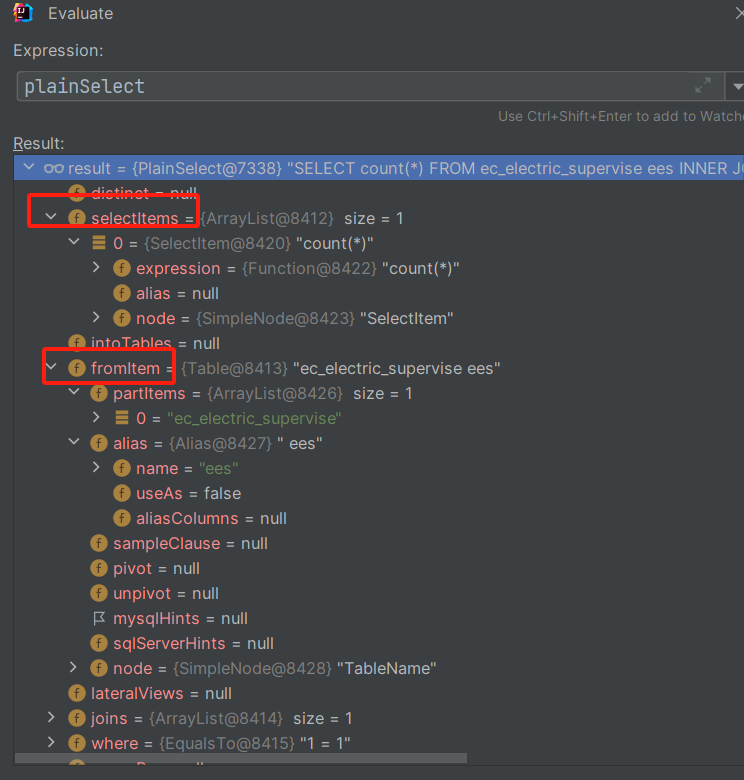
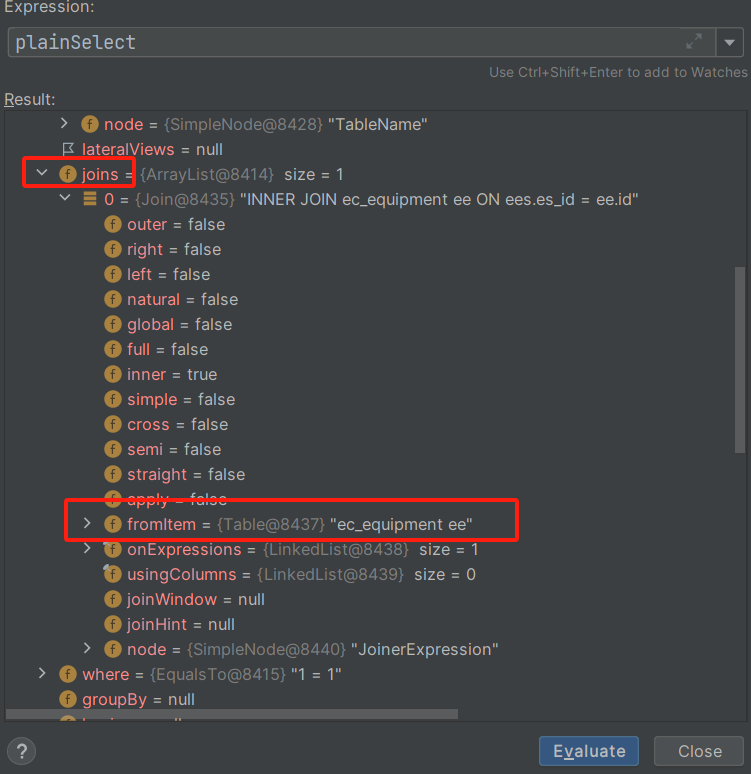
基本上能够想到的关于SQL的东西里面都有,可以做出更多的尝试,例如添加group by之类的。
3.2、1=1
可能有人注意到了,where标签下的第一个就是1=1,且在进行sql拼接的时候,预先append了一个and,即拼接后的sql是and(条件...),这样的目的是考虑到如果后续再添加必要的条件,且这个条件不能是页面操纵的,可以将1=1替换掉作为一个必定存在的条件。不喜欢这个的可以将这两个地方(位于getSqlSeg()方法和xml文件)的代码删掉。
3.3、代码块
代码块可以对类的构造器进行增强,类实例化的时候必须调用代码块中的内容不论是有参还是无参构造器都会执行,因此在代码块中对定义为final的HashMap进行填充,使其key为数字,value中包含连接条件。因为这个map是固定不变的,没必要每一次调用这个方法都去执行一次map的填充,因此将map定义为final,并在初始化的时候对其进行填充。
3.4、getSqlSeg()
之前有说过,这个方法是对sql进行预编译,并将里面的?占位符替换成真实的参数。那么他到底是怎么执行的呢?

warpper中有个sqlSwgment属性,其中包含了#{}这类占位符,而gettargetsql()这个方法则是对其中#{}部分进行了替换,替换成了?。
wrapper.getParamNameValuePairs()这个方法获取到的是属性值。
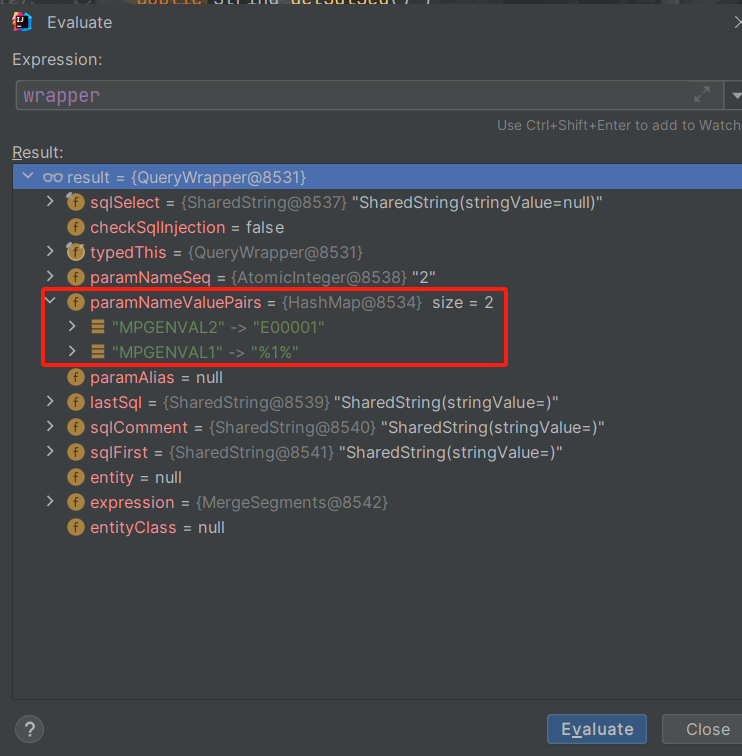
warpper中一大段的转entry的代码,最终目的就是获取"E00001"这类数据,并将其排序正确的顺序,最终在遍历targetsql,将其中的?替换成参数值。
具体过程可以打断点看值得变化。
目前来说,就这些东西。可能里面还有些东西没讲到,后续想到再更新吧。