1、kafka简介
上面是官方的解释。
在2.8版本之前,kafka和zookeeper是绑定关系,zk负责管理元数据、集群成员管理以及controller选举等。而为了提升性能以及降低运维的难度,kafka逐步移除了对zk的依赖,转而通过raft算法提升性能以及增强数据之间的一致性,最终实现了去zk化,当然也保留了zk,只是提供了另一种方式。
kafka是一个分布式流式处理平台,具有高吞吐,可持久化、可水平拓展、支持数据流等多种特性。
它的主要功能有:消息系统、存储系统、流式处理平台。具备解耦、冗余存储、缓冲、异步通信、可扩展性等特点。
2、kafka架构
kafka的架构体系中包含若干生产者、若干消费者、一个zk集群。生产者将信息发送至broker,broker将数据持久化到磁盘,消费者从broker中消费消息。
以下是kafka的基本概念:
1、producer:生产者,负责将消息发送至broker。
2、consumer:消费者,负责从broker消费消息。
3、broker:kafka服务节点。如果只有一个节点,同时也是kafka的服务器。
4、topic:主题。一个逻辑上的概念,可以有多个分区同一个topic不同分区下的数据是不一样的。
5、partition:分区。一个topic可以拥有多个partition。集群环境下partition分布在不同的的broker。目的是为了是按拓展性。
6、replica:副本。同一分区的副本保存的数据是一样的。副本能够保障当某个节点发生故障的时候,该节点partition上的数据不丢失。每个分区都可以有若干个副本,一个leader和若干个follower。
7、leader:分区中的主副本。生产者和消费者均只与leader交互。
8、follower:分区中从副本。负责同步leader的数据,同主副本保持一致。当leader发生故障时,从follower中选举出新的leader。
需要注意的是broker以及replica数量在集群配置时,在数量上应该保证为奇数。或者说涉及到主从节点的,数量都应该是奇数。奇数是为了能够顺利选举leader,同时也能够防止集群脑裂。
副本的数量应该小于等于broker的数量,分区的数量最好小于等于broker的数量。分区会按照一定的规则分配到不同的broker上,如果分区数量大于broker的数量的话,会导致一个broker上分配多个分区。副本是数据备份的数量,如果大于broker数量的话,这个topic是无法被创建的,所以数量必须是小于等于broker数量,且是奇数。
至于kafka的节点数量,自然也是奇数为优,同样为了防止脑裂,需要尽可能的在不同服务器之间金合理分配节点数量。
考虑到服务器之间的通信,并非服务器越多越好,服务器越多通信带来的延迟也越高。分区的备份数量也是需要综合考虑硬件资源,如果数据本身1G,备份两个就需要3G的空间。如果数据重要程度不高,能够承受节点故障恢复导致的数据丢失,可以不设置备份。
脑裂这个东西很抽象,假设3个节点部署在3个服务器,由于服务器之间的通信出了问题,主节点任然可用,只是无法和另外两个通信。于是两个从节点认为主节点挂了,于是兴高采烈的开始选举主节点,因为2>3/2,大于一半的节点,选举有效,所以产生了主节点,当原来的主节点恢复通信,再接进来就会发现,怎么两个我?想避免这种情况,只需要让非主节点的服务器中的节点数量不超过半数即可,不超过半数没办法成功选举。自然也就能避免脑裂。
但如果是上面的方案,主节点服务器宕机死掉了,主节点不工作,从节点选不出新的主节点,服务就受到影响了。这个暂时还没看到怎么解决,可能是集群套集群吧。
再说一下选举机制。当主节点下线之后,从节点发现了主节点下线,于是触发选举,选举开始时,每个节点都会投自己一票,这票的信息包括id和zxid。节点会将自己的票发送给剩余节点,收到票的节点则会把收到的票和自己的票做对比,优先对比zxid,zxid较大的更优先,zxid相同则id越大越优先,然后将自己的投票变更为收到的票中最合适的票,再次投出,当超过半数的票指向同一个节点时,该节点升级为主节点。
3、Windows启动kafka
安装kafka不在赘述,这里选择的是3.5.1版本,不算新,但也不算旧。在官网下载对应的zip文件解压缩即可。此外还需要scala,zookeeper(虽说2.8+版本就已经去zk化了),jdk也安装好,最好是安装新一点的11+,8估计也可以,jdk8已经是11年前的东西了,有些地方他已经不够看了。我这里装的是21。最后配置好环境变量。
【Kafka】Windows下安装Kafka(图文记录详细步骤)_windows安装kafka-CSDN博客
步骤可以看看这篇,应该大差不差,随便百度的。
3.1、zk环境下启动kafka(集群)
1、启动zk
控制台输入zkserver即可启动zk
2、启动kafka
进入到config文件夹,编辑kafka配置文件,主要是server.properties
broker.id=0
listeners=PLAINTEXT://localhost:port
advertised.listeners=PLAINTEXT://localhost:port
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=D:\\javareRource\\kafka\\logs\\92
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=3
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:port
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0关键参数:
id,每个id必须不同。
listeners:broker端口。加了adv的这个表示对外暴露的端口,集群会用到,两个保持一致就行。
log.dir:日志存放位置,因为考虑到集群,所以提前进行了分类存放
zk:最下面的zk参数,默认端口是2181,取决于你zk的端口。
3、通过控制台启动kafka
执行指令启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.propertieslinux环境下把bat换成.sh脚本即可,脚本文件路径去掉windows。
至此,单机版的kafka启动完毕。可以通过一系列指令使用kafka了。
4、启动kafka集群
同第3步。
复制两份配置文件,修改端口为93和94。我为了区分对配置文件进行了重命名,以端口号结尾。
启动指令如下
.\bin\windows\kafka-server-start.bat .\config\server93.properties
.\bin\windows\kafka-server-start.bat .\config\server94.properties至此,kafka集群启动完毕。
想要更多节点再复制配置文件启动即可。
为了尽可能的利用kafka的机制,最好是一个broker一个盘,但是没这个条件也没必要硬创造。
3.2、kraft环境下启动kafka(集群)
3.2.1、kraft配置文件解释
在同时支持zk和kraft的版本中,config文件夹中会存在另一个文件夹,这个文件夹中的是kraft启动的配置文件,实际用到的也是server.properties居多。如果是只支持kraft的版本的话config中不会有额外的文件夹。
下面简单介绍集群启动时,这个文件需要修改的部分。
配置文件的内容大致分为四类。
第一类:节点的基础信息
############################# Server Basics #############################
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093,2@localhost:29093,3@localhost:39093类型分为broker和controller,controller负责元数据管理,broker负责数据的存储,节点可以同时担任两个角色,也可以将这两个角色分开。
id必须在集群中唯一。
quorum:Controller 仲裁列表,用于连接到controller集群端点的列表。类似哨兵的角色。格式为id@ip:port。id和node.id保持一致,IP和端口和下面的配置保持一致。
仲裁分两类,一类是动态仲裁,另一类是静态仲裁。上面是静态仲裁,需要将所有的controller按照规则,全部登记在册。动态仲裁则是列出controller的ip和端口即可(也就少了两个字符...)。
基于kraft的集群应该首选动态仲裁,但动态仲裁对于kraft的版本有要求,必须大于等于1。否则只能使用静态仲裁。目前4.0版本不支持动态仲裁
关于动态仲裁主要是能够实现集群不停机拓展,静态仲裁则是需要集群停机再重启完成拓展。
动态仲裁拓展了kraft算法,引入了AddRaftVoter、 RemoveRaftVoter和UpdateRaftVoter。此外,还添加了两个新的元数据记录: KRaftVersionRecord和 VotersRecord 。这使得它可以动态的删除、添加、修改controller和对集群进行迁移。
没太多需要改的,节点的类型看需求改,可以把元数据管理和数据存储分开,也可以把元数据管理和元数据存储合并。
第二类:网络服务相关。包括监听的端口、节点间通信的名称、节点对外监听的端口、收发请求线程数量、收发数据字节数、处理网络请求的线程数量(包括磁盘io)、网络请求最大接收字节数、监听器所用的名称(逗号分隔)。
############################# Socket Server Settings #############################
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600controller.listener.names和listener.security.protocol.map是相匹配的,如果前者不设置,则默认使用PLAINTEXT。
大多数是默认,如果是集群部署在不同的服务器,默认就行,localhsot改成对应的服务器公网ip即可,如果是部署在同一台服务器的集群,端口也得改一下,非容器化部署的话就直接改ip,容器化不熟的话,改一下映射端口,例如29092:9092之类的。
第三类:日志相关。包括日志存放地点、每个主题数据备份数量、在启动和关闭时用于恢复日志的线程数、几个主题的复制因子
############################ Log Basics #############################
log.dirs= D:/javareRource/kafka4/1ka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1log.dirs:集群启动时,最好是多几个不同的目录,如果公用一个1ka,将会导致公用的文件有可能会被不同的broker写,最后导致程序异常(文件被占用)。
num.partitions:主题的备份数量。备份数量越多越安全,但是也将导致文件过多。
num.recovery.threads.per.data.dir:每个目录启动和停止是回复数据的线程数。在磁盘列阵中这个数值建议是大一些。
剩下的几个是主题的复制因子,不多说(我也不会到,官方没说)。这几个参数的值,在生产环境建议大一些,以确保可用性,参数参考值3,更大也行。
备份数建议等于controller数。
第四类:日志刷新策略。
############################# Log Flush Policy #############################
log.flush.interval.messages=10000
log.flush.interval.ms=1000log.flush.interval.messages:消息强制写入磁盘之前要接受的消息数量
log.flush.interval.ms:强制刷新日志之前消息可以停留的最长时间
这两个参数默认是关闭的。换言之,默认情况下消息是立即写入文件系统的。
没什么好说的,默认即可。
第五类:日志保留策略。
############################# Log Retention Policy #############################
log.retention.hours=168
log.retention.bytes=1073741824
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000‘log.retention.hours:日志保留时间。基于时间的日志保留策略。日志文件最短保留时间,超过这个时间的才可能会被删除。
’log.retention.bytes:日志保留字节数。默认是关闭的。基于大小的日志保留策略。日志文件达到指定大小后将被删除,和Hours独立运行,谁先执行,看谁先到达设定值。
‘log.segment.bytes:日志文件的最大大小,当日志文件达到这个大小时,将创建一个新的文件。
’log.retention.check.interval.ms:检测间隔,每隔指定时间检测一次在指定的保留策略下日志文件是否需要被删除。
这一类参数默认即可,没什么好说的。
3.2.2、windows环境kraft启动集群
创建3个文件夹,分别存放kafka文件
修改server.properties
修改内容参考上面的配置文件解释。必须修改的有 :node.id、端口、静态仲裁列表、日志文件位置。测试环节大多数保持默认即可。
############################# Server Basics #############################
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093,2@localhost:29093,3@localhost:39093
############################# Socket Server Settings #############################
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:9092
controller.listener.names=CONTROLLER
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
############################# Log Basics #############################
log.dirs= D:/javareRource/kafka4/1ka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
############################# Log Retention Policy #############################
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
在kafka目录下创建一个logs文件夹
使用指令格式化logs文件夹。个文件夹都用同一个uuid格式化。
# 生成一个uuid
.\bin\windows\kafka-storage random-uuid
# 结果
rEjD1Y3HRhCn_htSpzDemg
# 格式化存储
.\bin\windows\kafka-storage format -t rEjD1Y3HRhCn_htSpzDemg -c ./config/kraft/server.properties三最后启动集群,启动指令都是一样的。
# 启动指令
.\bin\windows\kafka-server-start ./config/server.properties测试集群,可以通过图形化界面来查看集群状况,测试创建topic、发送消息、消费消息之类的
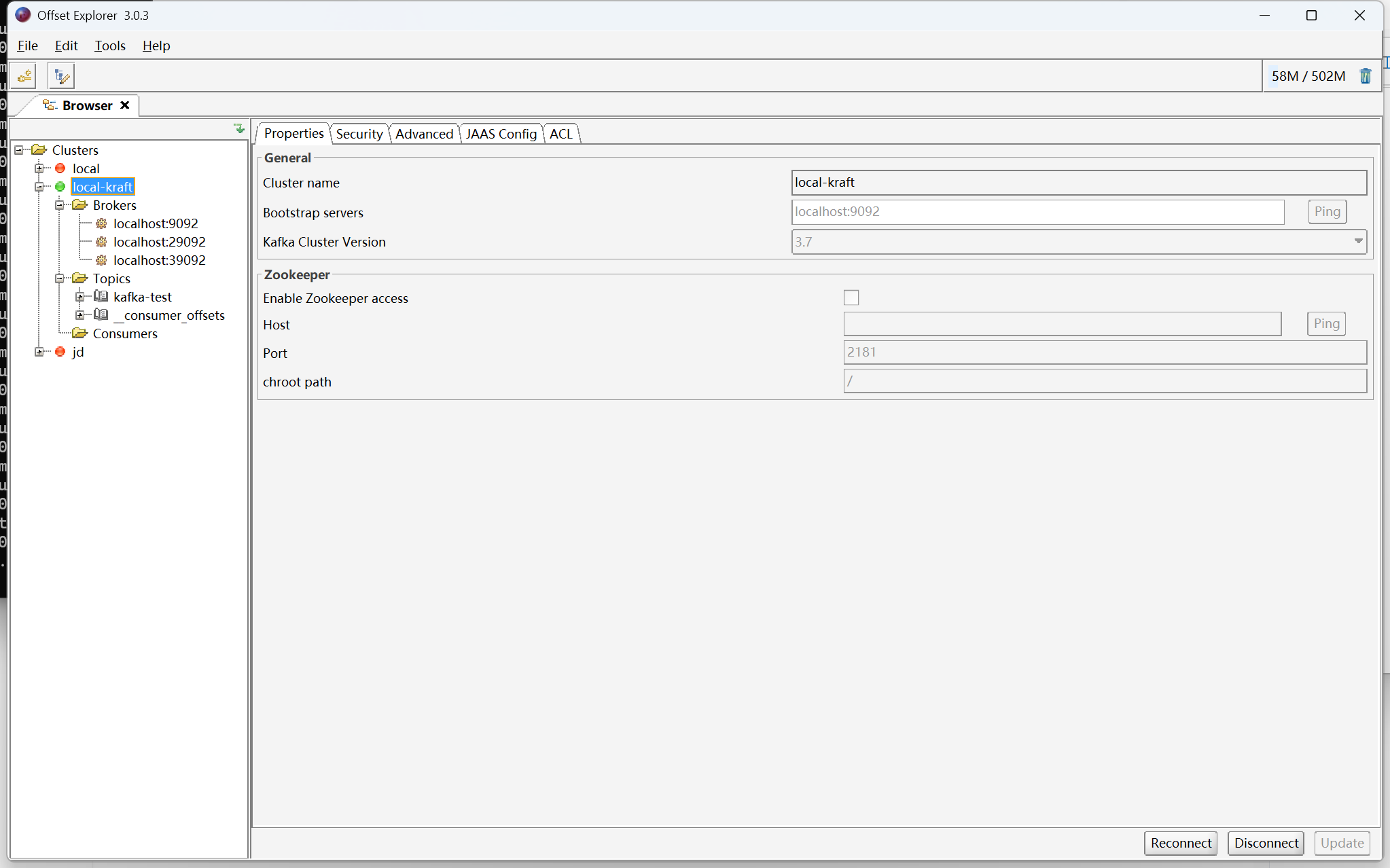
这个软件只能选到3.7版本,但是4.0也能用。
3.3、kafka基础指令
略。
3.4、kafka同步mysql数据
kafka除了作为消息队列工作之外还能做一些别的工作,例如同步不同数据库的数据。
这个我只有一个比较浅显的使用,并不是很成熟。
1、创建/修改配置文件
首先是在config文件夹下创建两个配置文件source.properties和sink.properties,名称随意。内容复制同目录下的connect-console-sink.properties和connect-console-source.properties。
对配置文件做如下修改:
source.properties:源数据库,数据流的起点
# source.properties
name=jdbc-source-mysql-01
tasks.max=1
topic=connect-test
# 修改内容
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
connection.url=jdbc:mysql://localhost:3306/activity
connection.user=root
connection.password=123456
# incrementing 自增
mode=incrementing
# 自增字段
incrementing.column.name=user_id
# 白名单表
table.whitelist=user
# topic前缀 mysql-kafka-
topic.prefix=mysql-01-
poll.interval.ms=60000url这一个参数,如果和我一样但不行的话,尝试换成项目里面的更长的那个url。
poll.interval是拉取间隔,我为了方便查看设置成了1分钟拉取一次。
# sink.properties
name=jdbc-sink-mysql-01
tasks.max=1
topics=mysql-01-user
# 新增内容
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
# 配置JDBC链接
connection.url=jdbc:mysql://localhost:3306/kafka_connect
connection.user=root
connection.password=123456
# 不自动创建表,如果为true,会自动创建表,表名为topic名称
auto.create=false
# upsert model更新和插入
insert.mode=upsert
# 下面两个参数配置了以id为主键更新
pk.mode = record_value
pk.fields = user_id
#表名
table.name.format=kafka_mysqlsink的topic根据source文件的内容来定义,也可以在source中定义topic.name使得topic的名称不跟随表变化。
关键参数对印上就行,例如主键,自增键之类的。
具体的参数解释就不多说,因为官方文档没找见。更抽象的是--help都查不出什么有效指令,纯两眼一抓瞎。只能通过报错信息和控制台输出来一点一点调整。
修改连接流的配置文件
bootstrap.servers=localhost:port
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10
plugin.path=D:/javareRource/kafka/plugins
listeners=HTTP://:port2plugins的路径随意,port是kafka节点的端口,一致就行。port2默认是8083,单机部署没有这个参数都行,有这个参数可以改端口,集群的时候必须要这个参数。
2、配置jdbc链接环境
因为kafka本身不自带jdbc的链接条件,所以需要配置好响应的环境,就像写代码导入依赖一样。
首先是kafka-connect-jdbc
下载地址:JDBC Connector (Source and Sink) | Confluent Hub: Apache Kafka Connectors for Streaming Data
版本随便选,不行就换个版本,反正文件是在这里下载。
然后是mysql驱动,上面的依赖不带jdbc驱动,如果缺少jdbc驱动的话,启动会报错:no suitable driver之类的。
mysql驱动下载地址:MySQL :: Download Connector/J
选择platform independent,然后选个适合自己jdk版本的驱动
然后在kafka的根目录创建一个plugins的文件夹,解压缩kafka-connect-jdbc,再把驱动放到解压缩后的lib文件里面,和kafka-connect-jdbc的jar包放一起,不然扫描可能扫描不到。
3、启动工具
启动指令如下
bin/windows/connect-standalone.bat config/connect-standalone.properties config/source.properties config/sink.properties这个指令第一部分是启动脚本,第二部分是启动的配置文件,单机启动或者集群,第三部分是配置文件集合,多个配置文件空格隔开即可。
至此,就可以实现数据库之间的同步,由于文档不够全面,所以按照上面的配置的话只能实现增量同步,修改删除是不会被同步的。
默认的查询sql是,理论上是可以修改的。
SELECT * FROM `activity`.`user` WHERE `activity`.`user`.`user_id` > ? ORDER BY `activity`.`user`.`user_id` ASC下面是一些可能得配置内容,启动时控制台输出的内容
source:
SourceConnectorConfig values:
config.action.reload = restart
connector.class = io.confluent.connect.jdbc.JdbcSourceConnector
errors.log.enable = false
errors.log.include.messages = false
errors.retry.delay.max.ms = 60000
errors.retry.timeout = 0
errors.tolerance = none
exactly.once.support = requested
header.converter = null
key.converter = null
name = jdbc-source-mysql-01
offsets.storage.topic = null
predicates = []
tasks.max = 1
topic.creation.groups = []
transaction.boundary = poll
transaction.boundary.interval.ms = null
transforms = []
value.converter = null
-------------------------
JdbcSourceConnectorConfig values:
batch.max.rows = 100
catalog.pattern = null
connection.attempts = 3
connection.backoff.ms = 10000
connection.password = [hidden]
connection.url = jdbc:mysql://localhost:3306/activity
connection.user = root
db.timezone = UTC
dialect.name =
incrementing.column.name = user_id
jdbc.credentials.provider.class = class io.confluent.connect.jdbc.util.DefaultJdbcCredentialsProvider
mode = incrementing
numeric.mapping = null
numeric.precision.mapping = false
poll.interval.ms = 60000
query =
query.retry.attempts = -1
query.suffix =
quote.sql.identifiers = ALWAYS
schema.pattern = null
table.blacklist = []
table.monitoring.startup.polling.limit.ms = 10000
table.poll.interval.ms = 60000
table.types = [TABLE]
table.whitelist = [user]
timestamp.column.name = []
timestamp.delay.interval.ms = 0
timestamp.granularity = connect_logical
timestamp.initial = null
topic.prefix = mysql-01-
transaction.isolation.mode = DEFAULT
validate.non.null = true sink:
JdbcSinkConfig values:
auto.create = false
auto.evolve = false
batch.size = 3000
connection.attempts = 3
connection.backoff.ms = 10000
connection.password = [hidden]
connection.url = jdbc:mysql://localhost:3306/kafka_connect
connection.user = root
date.timezone = DB_TIMEZONE
db.timezone = UTC
delete.enabled = false
dialect.name =
fields.whitelist = []
insert.mode = upsert
jdbc.credentials.provider.class = class io.confluent.connect.jdbc.util.DefaultJdbcCredentialsProvider
max.retries = 10
mssql.use.merge.holdlock = true
pk.fields = [user_id]
pk.mode = record_value
quote.sql.identifiers = ALWAYS
replace.null.with.default = true
retry.backoff.ms = 3000
table.name.format = kafka_mysql
table.types = [TABLE]
timestamp.fields.list = []
timestamp.precision.mode = MICROSECONDS
trim.sensitive.log = false
-------------------------
SinkConnectorConfig values:
config.action.reload = restart
connector.class = io.confluent.connect.jdbc.JdbcSinkConnector
errors.deadletterqueue.context.headers.enable = false
errors.deadletterqueue.topic.name =
errors.deadletterqueue.topic.replication.factor = 3
errors.log.enable = false
errors.log.include.messages = false
errors.retry.delay.max.ms = 60000
errors.retry.timeout = 0
errors.tolerance = none
header.converter = null
key.converter = null
name = jdbc-skin-mysql-01
predicates = []
tasks.max = 1
topics = [mysql-01-user]
topics.regex =
transforms = []
value.converter = null
-------------------------
ConnectorConfig values:
config.action.reload = restart
connector.class = io.confluent.connect.jdbc.JdbcSinkConnector
errors.log.enable = false
errors.log.include.messages = false
errors.retry.delay.max.ms = 60000
errors.retry.timeout = 0
errors.tolerance = none
header.converter = null
key.converter = null
name = jdbc-skin-mysql-01
predicates = []
tasks.max = 1
transforms = []
value.converter = nullstadnalone:
access.control.allow.methods =
access.control.allow.origin =
admin.listeners = null
auto.include.jmx.reporter = true
bootstrap.servers = [localhost:9092]
client.dns.lookup = use_all_dns_ips
config.providers = []
connector.client.config.override.policy = All
header.converter = class org.apache.kafka.connect.storage.SimpleHeaderConverter
key.converter = class org.apache.kafka.connect.json.JsonConverter
listeners = [HTTP://:8084]
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
offset.flush.interval.ms = 10
offset.flush.timeout.ms = 5000
offset.storage.file.filename = /tmp/connect.offsets
plugin.path = [D:/javareRource/kafka/plugins]
response.http.headers.config =
rest.advertised.host.name = null
rest.advertised.listener = null
rest.advertised.port = null
rest.extension.classes = []
ssl.cipher.suites = null
ssl.client.auth = none
ssl.enabled.protocols = [TLSv1.2, TLSv1.3]
ssl.endpoint.identification.algorithm = https
ssl.engine.factory.class = null
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.certificate.chain = null
ssl.keystore.key = null
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLSv1.3
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.certificates = null
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
task.shutdown.graceful.timeout.ms = 5000
topic.creation.enable = true
topic.tracking.allow.reset = true
topic.tracking.enable = true
value.converter = class org.apache.kafka.connect.json.JsonConverter上面有可能有一些配置内容
最后再贴一个帖子:字节面试官狂问我:kafka 是什么?有什么作用?-阿里云开发者社区
4、linux启动kraft集群
4.1、配置文件
同3.2.1节。
因为是容器启动,所以基本上不需要修改太多,三个文件除了nodeid和日志文件位置,advertised.listeners的ip需要改成公网ip,其余涉及到IP的地方换成容器IP,其余的都保持一致就行。
日志文件的位置要和后面4.3节的挂载目录一致,默认的没有任何问题,如果改了位置有可能会因为权限不足无法在容器内部创建文件夹导致容器无法启动或者启动后目录无法挂载。
############################# Server Basics #############################
process.roles=broker,controller
node.id=3
controller.quorum.voters=1@容器ip:9093,2@容器ip:9093,3@容器ip:9093
############################# Socket Server Settings #############################
listeners=PLAINTEXT://容器ip:9092,CONTROLLER://容器ip:9093
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://公网ip:39092
...
############################# Log Basics #############################
log.dirs= /tmp/kraft-combined-logs其余部分保持原样就行
4.2、挂载目录及文件
由于数据是存放在容器中,而容器销毁之后就会导致容器内部数据消失,因此将数据挂载出来可以保护数据,同时挂载4.1节中的配置文件,让容器按照4.1节的配置文件创建。
4.3、compose文件
为了方便容器之间通信,需要创建一个网络,创建网络的指令如下
docker network create name --gateway ip --subnet ip/24docker-compose.yml文件如下
version: "3"
services:
kafka01:
image: 'apache/kafka:4.0.1-rc0'
container_name: kafka01
ports:
- "9092:9092"
volumes:
- "./1ka/logs:/tmp/kraft-combined-logs"
- "./1ka/server.properties:/etc/kafka/docker/server.properties"
privileged: true
networks:
kafka_net:
ipv4_address: ip
kafka02:
image: 'apache/kafka:4.0.1-rc0'
container_name: kafka02
ports:
- "29092:9092"
volumes:
- "./2ka/logs:/tmp/kraft-combined-logs"
- "./2ka/server.properties:/etc/kafka/docker/server.properties"
privileged: true
networks:
kafka_net:
ipv4_address: ip
depends_on:
- kafka01
kafka03:
image: 'apache/kafka:4.0.1-rc0'
container_name: kafka03
ports:
- "39092:9092"
volumes:
- "./3ka/logs:/tmp/kraft-combined-logs"
- "./3ka/server.properties:/etc/kafka/docker/server.properties"
privileged: true
networks:
kafka_net:
ipv4_address: ip
depends_on:
- kafka01
- kafka02
networks:
kafka_net:
driver: bridge
external: true
ipam:
config:
- subnet: "ip/24"
gateway: "ip"yml文件需要注意缩进,这个格式对缩进要求非常严格,如果缩进有问题启动会报错。
容器内部日志位置默认在/tmp/kraft-combined-logs,配置文件路径在/etc/kafka/docker/server.properties,otp路径下也有配置文件,但这个配置文件不让修改,无法通过挂载来覆写,实际上使用也不是opt路径下的配置文件。
4.4、启动容器
相关指令
# 后台启动,不带d是前台启动
docker compsoe up -d
# 关闭并销毁容器
docker compose down容器启动成功
kafka01 | [2025-08-07 06:07:39,072] INFO [KafkaRaftServer nodeId=1] Kafka Server started (kafka.server.KafkaRaftServer)
kafka03 | [2025-08-07 06:07:39,074] INFO [KafkaRaftServer nodeId=3] Kafka Server started (kafka.server.KafkaRaftServer)
kafka02 | [2025-08-07 06:07:39,011] INFO [KafkaRaftServer nodeId=2] Kafka Server started (kafka.server.KafkaRaftServer)